Experience Serverless with AWS

As a developer, I understand when a new technology comes along to the world, it is initially a bit confusing to get picked up. Particularly, if it is a game changer which is introducing new concepts.
I reckon one of the most efficient ways of picking up and learning new stuff is making relevant and smart questions which can lead us to the best possible answers. So, I practiced making some questions about Serverless and tried to answer them in the scope of the article as much as I could.

What is Serverless ?
In cloud computing, you can run your code without provisioning or managing servers. Awesome, but why and how?????
Why Serverless?
First thing first, lets see what sort of issues we had and who was suffering the most? and who should be happy with this service?
Developers? Project managers? Devops? Clients?
I am pretty sure none developer have a desire to go through pain of server configuring like IIS setup, routing issues ... only because they want to run a piece of code as an API or any backend code!!!!
Once you allocate a server to your code, devs/devops should make sure the server is secure, install daily or weekly basis patches, updates and other stuff on the server. No developer also like to stick with old scholl technologies once more efficient ones are out there!!!!
Project managers and clients are also concerned about the price they have to spend on allocating EC2s, ELBs and other resources to a project. They also need to make sure that the server can be scaled up and down to avoid any issue including performance and financial.
So, that's great if Serverless can help all of us to simplify whole process with writing the code, deploy it easily and only pay for the invocation time of the services without being worried about server provisioning and maintenance.


What category of cloud computing Serverless is?
Serverless architectures is about running the code in stateless containers that are event-triggered. One way to think of this is:
FaaS ‘Functions as a service’
Since it is a cloud service, you can go for any provider you prefer.
Each platform name Serverless service differently:
- Lambda functions in AWS
- Azure function in Azure
- Cloud function in Google
What AWS lambda (known as Serverless) can really do?
Since in this article we evaluate and discuss Serverless as an AWS Webservice, lets see what it can really offer:
- AWS Lambda lets you run code without provisioning or managing servers
- With Lambda, you can run code for virtually any type of application or backend service
- All with zero administration. Just upload your code and Lambda takes care of everything required to run
- Scale your code with high availability.
- You can set up your code to automatically trigger from other AWS services
- Or call it directly from any web or mobile app
Enjoy other benefits like:
7. Simple deployment process: It is pretty quick so you just need to provide standard configuration in your code, write your functions and zip it up.
8. Pay-for-what-you-use: you only pay for the invocation time of your service
For AWS lambda function which languages can we code up with ?
- Node.js v4.3.2 and 6.10.2
- Java
- Python
- .NET Core (C#)
Myth of Serverless, how it works without Server?
It is important to dispel a myth that there is no server to run the code!
AWS Lambda execution environment is based on a Linux AMI which is a very light version of Linux Instances (EC2). Per each invocation, AWS lambda launches a container (an execution environment) to handle the request. However, this is not our concern to take care of the server and maintain it.
It takes time to set up a container and get it bootstrapped, which adds some latency each time the Lambda function is invoked. However, Lambda tries to reuse the container for subsequent invocations. It means AWS Lambda maintains the container for some time in anticipation of another Lambda function invocation.
This knowledge can impact your code, since you can add logic in your code to check if some resources such as a DB connection already exists before creating one.
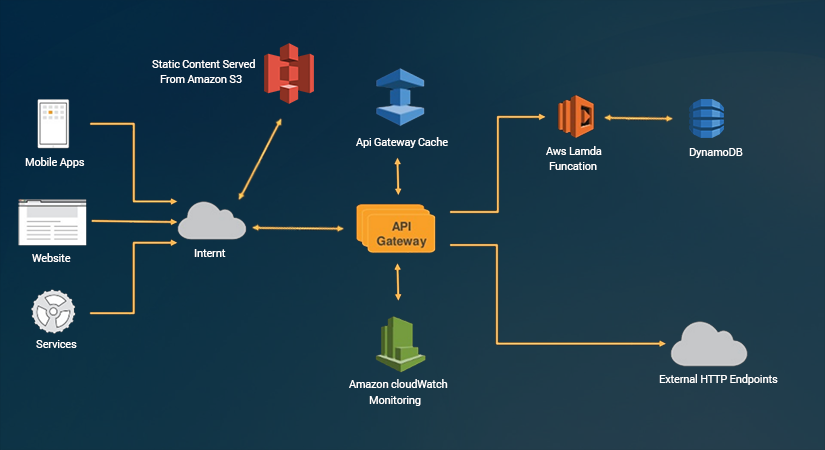
How lambda function is separated from Api Gateway?
There are basically two terminologies regarding Serverless technology which is a bit confusing for newbies.
When we talk a bout lambda function, it is an abstract function which can be run by any other AWS services icludinh kenisis, S3, SNS, DynamoDb, API gateway,... So, the function itself is not an API, it is a independent abstract unit of code.
API Gateway though is an HTTP server where routes the requests to the associated lambda function. If you are familiar with the concept of Api Proxy, you can simply match the concept with API Gateway.
However, API Gateway is way beyond just a router. It is a service that allow developers config their lambda function, map http request parameters to inputs arguments for the lambda function and transforms the result to an http response, and returns this to the original invoker.
It also, provide a dashboard to test the lambda functions and provide visibility by displaying log and outputs in detail.
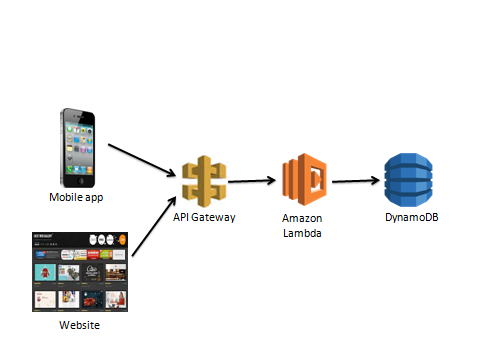
How to build a lambda function and API Gateway?
Have a look at this repo to have a clear idea.
What's the Best practice to Deploy a lambda function?
There are two ways to create and deploy lambda functions:
1. Code up and deploy it manually by using wizards in AWS console:
In fact, in this method when you have small piece of code without any dependency on other libraries and mostly for training purposes you can write inline code directly in the console or you can write it in other IDEs and upload your code.
drawbacks:
- Manually upload your code (from your computer or S3)
- Configure your function as well as API Gateway including role and policy assignments and method creation(get/post,...)
- Log configuration
- You cannot leverage reusability so if you decided to move your lambda functions and API Gateway to the Production, you have to go through all the manual steps from the scratch.
- No integration with CI/CD pipeline
2. Automatic deployment through Serverless (or any tool):
With automated deployment, you won't have above issues and at the moment it is the best practice for deployment. However,currently there is no built-in option in AWS to deploy the code from your local machine directly to the AWS server. Therefore you need to use some third party frameworks to help with deployment like Serverless and Apex
By using serverless framework (confusing name :) but it regards the deployment tool), The main benefit will be using cloudformation and stack creation which can manage everything in one go.
Another benefit is you can code up and deploy your code with this tool to different platforms like Azure, AWS,...
Once you are ready to deploy your code, simply take these steps to run your code in dev AWS environment (up to you to chose the stage) :
npm install
sls deploy -v --stage dev --region ap-southeast-2
Beside all the benefits, you might be limited by using the tool to some provided features and experience some breaking changes in each release.
What Permissions, roles, Policies and resources we need to introduce?
There are some security and restrictions around your lambda. execution permissions and invocation permission. The lambda needs to have execution permission in order to have access to the aws resources like s3, dynamo db ,...
Each function needs to be assigned to a role and the basic policies for the role is allowance to read and write to the logs
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
so you can assign the lambda_basic_execution role or create a role with same policies but specific for your function.
For the invocation permission you need to confirm that your API gateway has enough permission to invoke your lambda function.
Once we deploy our code with automated tools like Serverless framework, it needs to have a placeholder bucket in s3 so the zipped package and code can be put up there.
If we are using any dependent aws resources, it is much better to introduce them in config file(serverles.yml) as a dependent resource, then all the proper policies and permissions on the associated resource will be perfectly done.
resources:
Resources:
S3BucketChocoApi:
Type: AWS::S3::Bucket
Properties:
BucketName: ${opt:stage}-choco-api
However, since the resources are now part of the stack, if you try to delete the stack you might face some errors. Like the S3 bucket is not empty. You just need to go and delete the files inside the bucket.(leave the actual bucket itself stays and get managed by stack)
Just keep in mind that from the user perspective if you have an account with AWS, you also need to add a permission to execute the AWS lambda.
What is the process of creating whole stack in aws once you deploy the code?
This is all the steps serverless would run for you to prepare the environments and deploy your code.
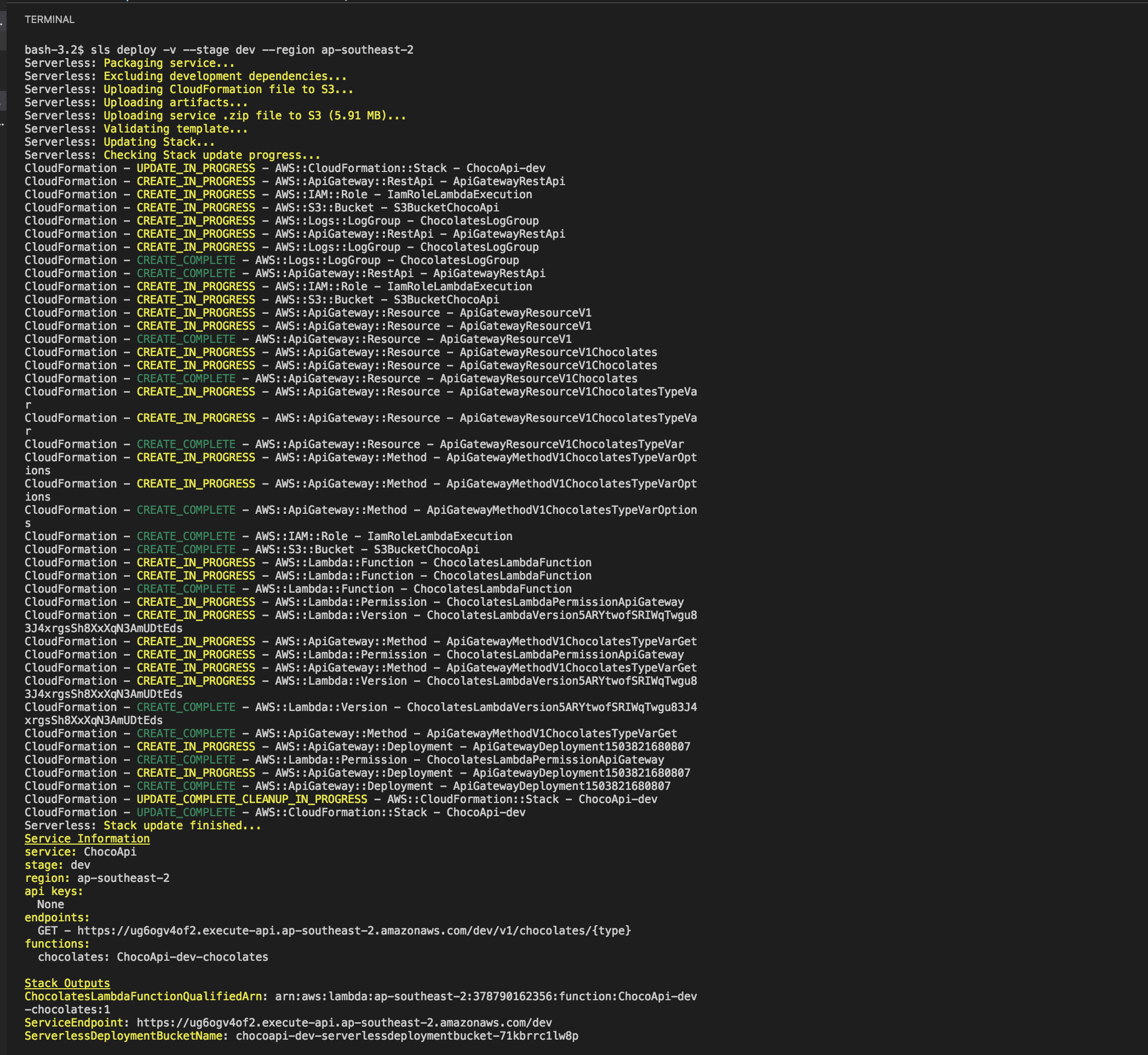
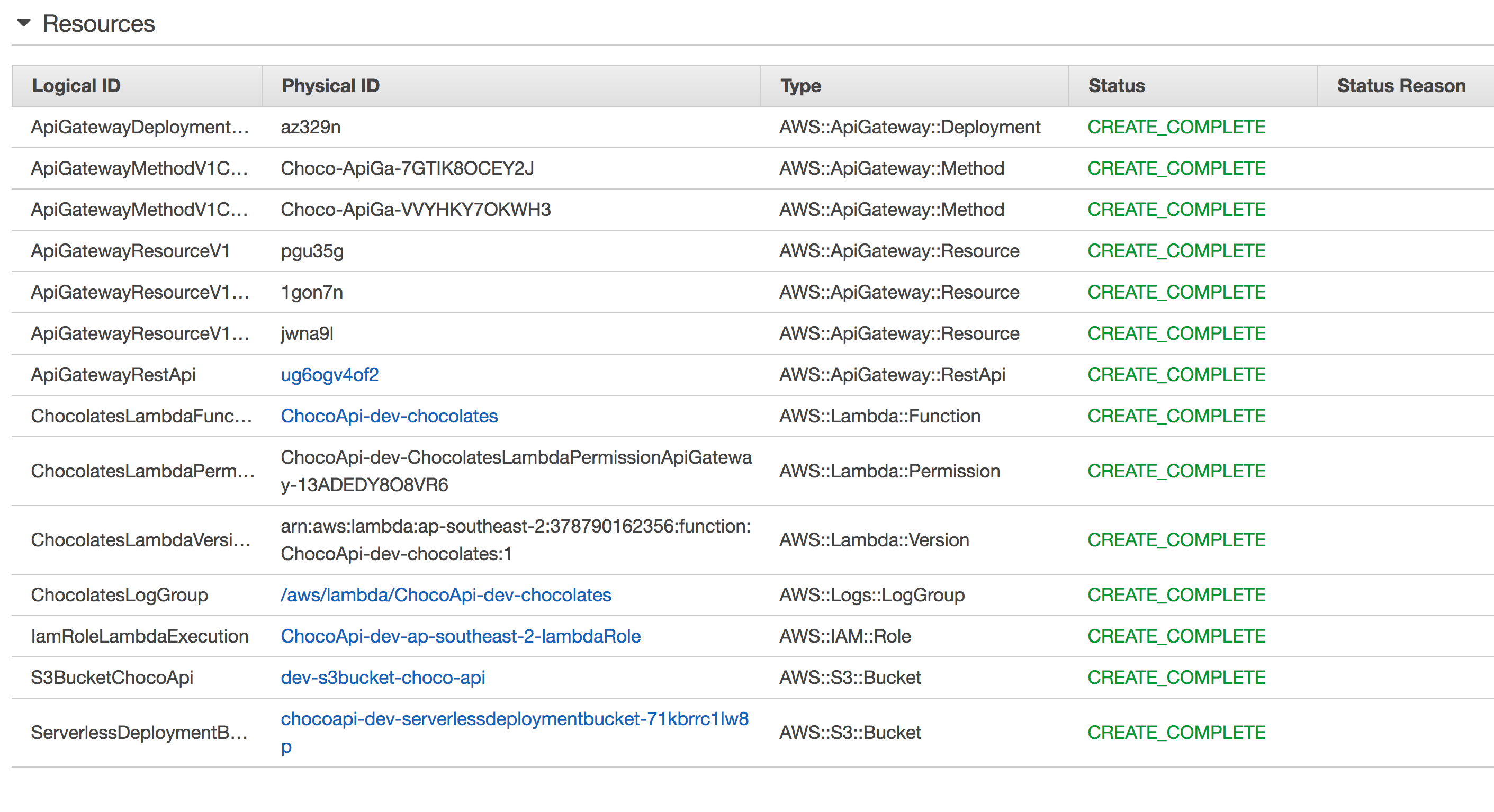
Also here is the list of all resources we need for executing the function :
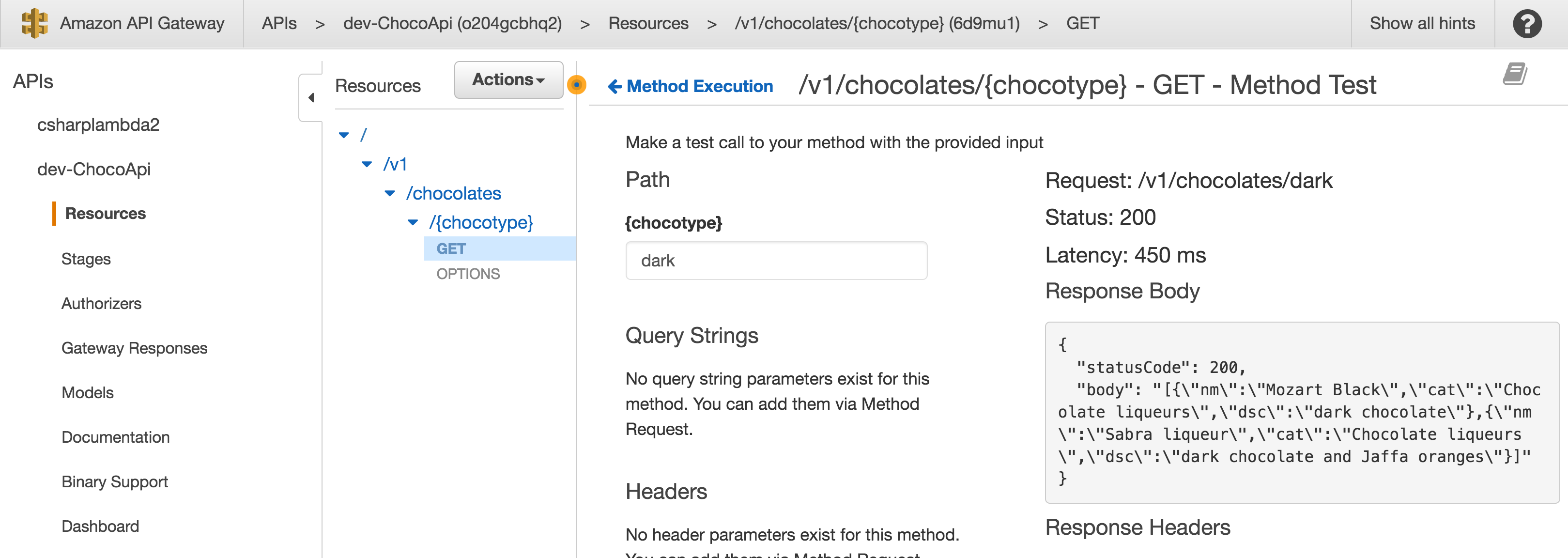
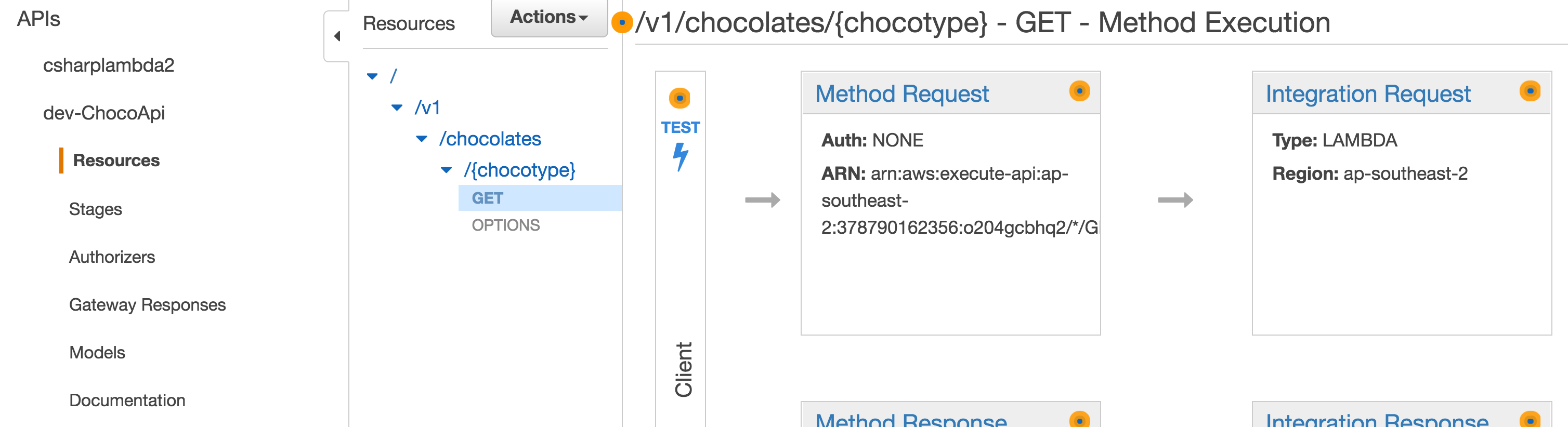
How to test the API?
Simply go to the API gateway service in AWS console, find your resource and
click the TEST it as below:
You can also get the public url andtest your function in Postman or anywhere else. So, from Dashboard panel get the url and your resource name. Make sure the path is correct otherwise most likely you will get this error.
{
"message": "Missing Authentication Token"
}
How concurrency matter in lambdas?
In fact there is a limitation regarding the number of concurrent request per second across all functions when events including Api Gateway, S3, SNS or etc hits the endpoint
Probably you can not assume a valid number of concurrent request immediately but after you watched the performance and logs for a while, you can estimate much more accurately.
You can use the following formula to estimate your concurrent Lambda function invocations:
events (or requests) per second * function duration (by log watching)
Do we need to setup VPC?
Theorically, when we deploy our lambda, it is publically accesible by API gateway. However, for other resources which are inside the VPC, you need to set permissions to your lambda then they can communicate with one another.
VPC is a virtual network dedicated to your AWS account. It is logically isolated from other virtual networks in the AWS Cloud. You can launch your AWS resources, such as Amazon EC2 instances, into your VPC.
So, here is the code you need to provide in your serverless config.Also with Security groups you can control the ingress and outgress resource IPs.
iamRoleStatements:
- Effect: Allow
Action:
- ec2:CreateNetworkInterface
- ec2:DescribeNetworkInterfaces
- ec2:DeleteNetworkInterface
Resource: "*"
Drawbacks of AWS lambda:
- Testing the function in local environment is a bit tricky.
In fact you need to look at the log to see errors. You also can use some 3th party libraries to debug which is not convenient enough.
You also need to mock your function handler (not the actual code) with express or any local server. - No built in deployment tools
- Lambda function is stateless so you need to be prepared for other caching solutions if you need. Like Redis or ...
- Versioning is not still perfect. So, if you decide to support multiple versions for multiple users it would be hard since Serverless deployment tool will override old config by removing and updation stack in each release so you need to find a work around.